When your ears don’t get the final say
People notice it most on a video call. Someone’s audio is a little glitchy, and suddenly the words feel harder to catch. It isn’t one famous event in one place. It turns up anywhere there’s speech and a face to watch: a Zoom meeting in the US, a noisy train platform in Japan, a classroom in the UK. The McGurk illusion is the name for a specific version of this. When the mouth movements say one sound and the audio says another, the brain often “hears” a third thing that isn’t actually in the audio track.
The classic mismatch that creates a new sound

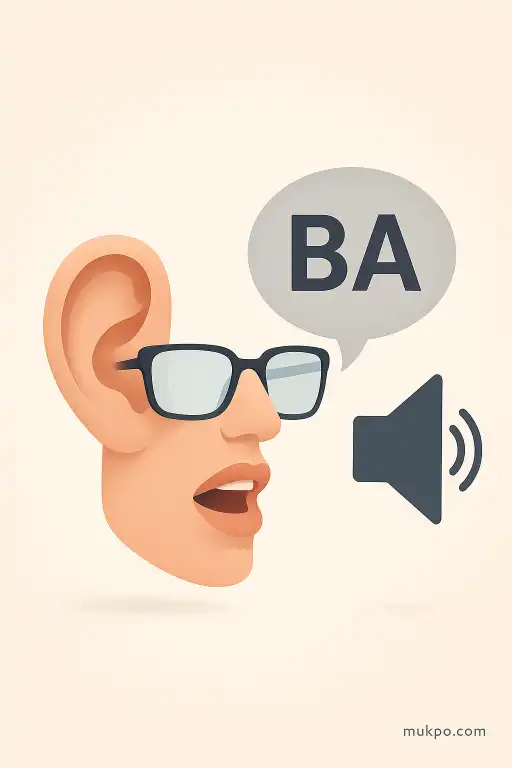
The best-known setup is simple. A video shows a person silently mouthing “ga,” while the soundtrack plays “ba.” Many people report hearing “da” or “tha” instead. Nothing is wrong with their ears. They are not misreading lips on purpose either. The percept is fused. It feels like one coherent syllable coming from one person.
This is why the illusion surprises people. It doesn’t feel like vision is “adding a hint.” It feels like hearing itself has changed. And it often persists even when someone knows exactly what the trick is, because the cue from the mouth arrives at the same time as the cue from the sound and the brain treats them as parts of one event.
Why the brain mixes lips and sound
Speech is not just an audio signal. A moving mouth carries reliable information about where in the vocal tract a sound is made. “Ba” is typically made with the lips closing. “Ga” is made farther back. When those cues conflict, the brain tends to settle on something that fits both inputs reasonably well. A middle option like “da” can match the heard voicing and the seen place of articulation better than either source alone.
A detail people usually overlook is timing. The illusion is strongest when the mouth movement and the audio line up closely. If the mouth clearly leads or lags the sound by enough milliseconds, fusion becomes less likely. The same physical clip can feel different after a platform introduces a small audio delay, which is one reason the effect gets talked about during streaming and video chat.
When it’s strong, when it fades, and why it varies
Not everyone experiences the same result. Some people keep hearing the original audio. Others get a strong fused syllable. The strength varies with the clarity of the video, the loudness and quality of the sound, and the specific consonants involved. It also varies across people for reasons that are not always clear. Differences in attention, sensory weighting, and experience with reading faces can all matter, but there isn’t a single knob that predicts it perfectly.
The illusion also depends on how “speech-like” the situation is. If the visual track looks like a real face producing speech, the brain treats it as a useful cue. If the mouth is obscured, badly lit, or moving in a way that doesn’t match normal articulation, visual influence tends to drop. The same goes for audio that is clearly synthetic or distorted enough that it no longer reads as ordinary speech.
What it reveals about everyday listening
The McGurk illusion is a clean demonstration of something that’s usually invisible: hearing speech is already a multi-sensory task. In a quiet room, it can feel like the ears are doing all the work. But the brain is constantly combining cues about identity, location, and articulation. Vision often supplies some of the most dependable structure, especially for consonants that are brief and easy to mask with noise.
That’s why a small change in what’s visible can change what seems audible. A camera angle that hides the lips, a face turned slightly away, or a low frame rate that blurs mouth shapes can all shift what people think they heard, even if the audio waveform never changes. In real conversations, the same mechanism helps listeners stay locked onto the right talker in a busy room, because the face helps the sound stay “owned” by one source.
Related reads
- Why your brain needs extra time to wake up fully after sleep
- How backyard bird feeders reshape which songbirds visit your neighborhood
- A subway tile with a fossil trapped inside it since the station was built
- The Victorian coroner whose seaside inquest revealed a chemist’s lethal whitening brew
- Why a song suddenly gives you chills and goosebumps
- How bioluminescent plankton make whole waves glow at night